I was first introduced to this problem from Leonard Mlodinow's "The Drunkard's Walk: How Randomness Rules Our Lives" and immediately "fell for the trap". The problem exists in two parts, the first (easy) part followed by the second (hard) part. The easy part is as follows:
Say you know a family has two children, and further that at least one of them is a girl. What is the probability that they have two girls?
An easy way to do this is to list out the possibilities:
- Boy-Girl
- Girl-Boy
- Girl-Girl
Say you know a family has two children, and further that at least one of them is a girl named Florida. What is the probability that they have two girls?At first I didn't think it would make any difference. How could knowing the name of the child change the chances for two girls? So I didn't believe the author (at first) that the chances were even, p=0.5, for the family to have two girls. Again we can list off the possibilities:
- Boy-Girl (Florida)
- Girl (Florida)-Boy
- Girl (Not Florida)-Girl (Florida)
- Girl (Florida)-Girl (Not Florida)
- Girl (Florida)-Girl (Florida)
- write a simulation which reproduces it
- show that a formal analysis works for the problem
Probability for a girl to be named Florida: 0.01 Total number of families with two children: 1000000 999862 girls (0.499931 of children) 249745 both girls (0.249745) 750117 families with girls (0.750117) 249745 both girls (0.332941) given families with girls 10084 families with a girls named florida 4997 both girls (0.495537) given families with girl named floridaThe formal analysis gets interesting, because I want to understand how the frequency, f, of the name affects the probability of having two girls. If it is a rare name (f ~ 0) then I should get p=0.5. For a common name (f ~ 1) then I should get p=1/3. Not that with f=1 then the word "name" is a little odd because all girls have it, so one might think of it as a label (like "has a nose"). First some notation:

Applying Bayes theorem to the easy problem, we get:
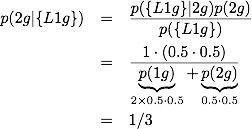
The hard problem is set up like:
It is clear that p({L1g}|2g)=1 whereas p({L1g},F|2g)=1 is not: given that we have 2 girls, we definitely have at least one girl, but we need not have at least one girl named Florida. Breaking the second term up we get
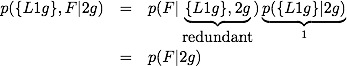
Now we have
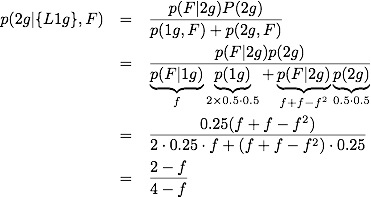
It is easy to check that it has the right limits:
I'm not sure if there is a better way to address this problem, but the analysis and simulation agree, and further we have a very simple form for how the probability depends on the frequency of the known label (e.g. Florida).
Code for simulation
from pylab import *
from numpy import *
# 2 daughter problem
num_families=1000000
num_children_per_family=2
f_girls=0.5
f_florida=0.01
print "Probability for a girl to be named Florida: ",f_florida
print "Total number of families with two children: ",num_families
child_types=['boy','girl']
families=[ (child_types[randint(2)],child_types[randint(2)]) for x in range(num_families)]
names=[]
for f in families:
if f[0]=='boy':
name1='Bob'
else:
name1='Florida' if rand() < f_florida else 'Sarah'
if f[1]=='boy':
name2='Bob'
else:
name2='Florida' if rand()< f_florida and name1!='Florida' else 'Sarah'
names.append( (name1,name2) )
# total fraction of children as girls
girls=0
children=0
for f in families:
for c in f:
children+=1
if c=='girl':
girls+=1
print "%d girls (%f of children)" % (girls,float(girls)/children)
# total fraction of families with both girls
both_girls=0
for f in families:
if f[0]=='girl' and f[1]=='girl':
both_girls+=1
print "%d both girls (%f)" % (both_girls,float(both_girls)/num_families)
# total fraction of families with both girls GIVEN that the family has a girl
families_with_girls=[]
for f in families:
if f[0]=='girl' or f[1]=='girl':
families_with_girls.append(f)
num_families_with_girls=len(families_with_girls)
print "%d families with girls (%f)" % (num_families_with_girls,
float(num_families_with_girls)/num_families)
both_girls=0
for f in families_with_girls:
if f[0]=='girl' and f[1]=='girl':
both_girls+=1
print "%d both girls (%f) given families with girls" % (both_girls,
float(both_girls)/num_families_with_girls)
# total fraction of families with both girls GIVEN that the family has a girl named florida
families_with_florida=[]
for n,f in zip(names,families):
if f[0]=='girl' and n[0]=='Florida' or f[1]=='girl' and n[1]=='Florida':
families_with_florida.append(f)
num_families_with_florida=len(families_with_florida)
print "%d families with a girls named florida" % num_families_with_florida
both_girls=0
for f in families_with_florida:
if f[0]=='girl' and f[1]=='girl':
both_girls+=1
print "%d both girls (%f) given families with girl named florida" % (both_girls,
float(both_girls)/num_families_with_florida)
When you say that it's rare to have two girls with the name Florida, do you mean that it's unusual because the name is so uncommon? Does this simulation also take into account the unlikeliness of a family naming their two children the same name?
ReplyDeleteIs this a direct quotation from the original problem:
"Say you know a family that has at least one girl. What is the probability that they have two girls?"
Without specifying the number of children in the family, does this problem consider families with more than two children? You have three children, for example, which changes the probability of having two girls.
If you really want to get specific with the probability of having two girls, you could then look at the male lineage in the family to deduce the probability of having female children. In general, as a population, the ratio of males to females is approximately equivalent. However, individually, the probability of male or female children is not necessarily even.
First comment on the blog! Yay! :)
ReplyDeleteWhen you say that it's rare to have two girls with the name Florida, do you mean that it's unusual because the name is so uncommon? Does this simulation also take into account the unlikeliness of a family naming their two children the same name?
The answer is "no", it doesn't assume that no family would name their children the same thing. If you think of it as a label, rather than a name, then it makes more sense. You have labels that would be rare (e.g. "is named Florida"), medium rare (e.g. "has blue eyes"), and well done (e.g. "has a nose").
Is this a direct quotation from the original problem
Without having the book in front of me, no it's not a direct quote, but it captures the problem in a short space. Ah, I see now, I should have stated that the family has two children....I'll go back and modify this, because otherwise it gets complicated fast!
As for the probability of having a boy or a girl, actually p(boy) is a smidge higher than p(girl) even in the overall population. I haven't seen data in individual lineages. The nice thing about the analysis is that the probabilities are all explicit: you can go back and change p(boy) and p(girl) for your specific case, and follow through the same calculation.
This is one of the advantages to Bayesian analysis: all of the assumptions are right out there and explicit, so you can go back and modify anything that you think needs improvement. Many frequentist (or orthodox) methods have hidden assumptions that may, or may not, be true but are hard to figure out because you don't see them laid out in the analysis.
If all Florida-Florida are counted as Florida-GirlNotFlorida the math works out the same.
DeleteI understand that simply from a mathematical standpoint that "Florida" is more of a label for something rare or unusual instead of name for your friend's kid.
ReplyDeleteHowever, the -actual- probability would be affected because nearly no one (with the except of maybe George Foreman) would name their children the same name.
Yes, and as soon as you require that the girls have unique names, then the probability becomes 1/3, no matter how rare the name is.
DeleteIn your simulation, you establish the probability for a girl to be named Florida as being 1/100. But that actually corresponds to Barbara, the fourth most common name in the U.S.! Surprisingly, the simulation still works as expected.
ReplyDeleteThis shows that as long as we know that one of the girls has any trait which is uncommon, that will alter the probability of both children being girls from 1/3 towards 1/2 - and even a common name such as Barbara is uncommon enough for this matter!
The fact that parents avoid naming their children with the same name just makes the matter more confusing, since this point seems important but is irrelevant.
Mlodinow was very unfortunate in choosing "Florida" in his explanation of Bayesian analysis. In fact, he was unfortunate in choosing names at all. Using "girl with a mole on her left cheek" would have caused much less confusion.
Now, just to make things interesting: What would happen if we knew that one of the girls is left-handed?
I had meant to go back and change the probability to the actual fraction of Floridas in the population, but that is very interesting about Barbara!
ReplyDeleteWhat is also remarkable is that it doesn't matter whether they name only one of their daughters Florida. The expression for the probability comes out exactly the same. When evaluating P(F|2g), if the first daughter is Florida, then it is irrelevant if the 2nd one is Florida or not. It's easily confirmed with the following simulation too:
from pylab import *
from numpy import *
f=0.1
N=10000
r1=rand(N)
r2=rand(N)
N1=list(r1<f)
N2=list(r2<f)
case1=[n1 or n2 for n1,n2 in zip(N1,N2)]
print case1.count(True)/float(len(case1))
print f+f-f**2
nn=[]
for n1,n2 in zip(N1,N2):
if n1:
nn.append(False)
else:
nn.append(n2)
N2=nn
case2=[n1 or n2 for n1,n2 in zip(N1,N2)]
print case1.count(True)/float(len(case1))
``Mlodinow was very unfortunate in choosing "Florida" in his explanation of Bayesian analysis. ''
ReplyDeleteWhat I found is that Mlodinow did not do a Bayesian analysis at all, that he was definitely coming from a frequentist position. That, I found more unfortunate. :)
Finally, when I find a way to post code properly (looks like the code is getting mangled) I will go back and modify it.
ReplyDeleteI put a more detailed analysis of the case where you can't name two children Florida at http://bblais.blogspot.com/2010/02/coin-flips-and-names-evil-problems-in.html
ReplyDeleteBottom line...it doesn't change the analysis in this post at all.
"Say you know a family has two children, and further that at least one of them is a girl. What is the probability that they have two girls?" Unfortunately, this problem statement is ambiguous. To see why, just ask yourself "What is the probability that, for a family you know has two children but you only know of one gender for the pair, that you would know 'at least one of them is a girl?' What is the probability that you would know 'at least one of them is a boy?" Because the solution Brian Blais presented assumed those probabilities were 1 and 0, respectively.
ReplyDeleteEssentially, Brian assumed that "at least one is a girl" is both a necessary and sufficient condition for the construction of the sample space, both in his solution and in his simulation. But suppose you learned what you know about this family because you meet the mother walking with her daughter, and asked her how many children she has. When she said "two," this scenario fits the problem statement just as well as what Brian assumed. You know the family has two children, and that at least one is a girl. But, the probability is 1/2 that she has two daughters, not 1/3 (reference: Bar-Hillel and Falk, or look at Grinstead and Snell's on-line textbook). This is because "at least one is a girl" is just a necessary condition for the construction of this sample space. Since the woman had only a 50% chance to be seen walking with this child, instead of her other child; and that child could be a boy, there are possibilities where the family has "at last one girl" but you do not know that fact.
In order for 1/3 to be the correct answer, you have to "know the family has two children, and further that at least one of them is a girl" because you specifically sought that information, at that level of detail, about the family. And further, that you must find that out whenever it is true, which means somebody has to know both children. The alternative I described, where the probability is 1/2, happens anytime you learn the gender of one specific child. It is the correct answer regardless of how that specific child was selected, and regardless of whether you know how that child was selected.
Usually the question Brian asked is compared to "you know the older child is a girl," and the discussion implies you do need to know the method, without coming out and saying so explicitly. And the discussion also implies that "you know at least one is a girl" can't describe a specific child, but it can. I'll leave you to decide for yourself which scenario is more realistic, in general. But the problem is that this question is seldom worded "in general," and Leonard Mlodinow's treatment of it is a good example.
(Continued)
(... Continued)
ReplyDeleteThe difference plays a major role in the "trap" Brian described, not believing that knowing the girl's name is Florida affects the answer. The same distinction I described is required to get the (2-f)/(4-f) answer Brian derived. You have to specifically seek the knowledge "has two children, and further that at least one of them is a girl named Florida," at that level of detail, and with 100% accuracy. In particular, it applies only to that name, ignoring any other unusual name like "Cleopatra," or "Indiana" for a boy. Mlodinow, unfortunately, described a scenario where you remembered the family because of an unusual name, and used "Florida" only as an example. That makes the Florida a specific child, selected because her name was more unusual than her sibling's, and the probability is identically 1/2 (assuming, of course, that boys and girls are equally likely, and equally likely to have unusual names). Mlodinow also said, in both forms of the problem, that you do NOT remember whether both are girls. This implies you didn’t ever know, and the requirement for 100% accuracy fails. The answer to both forms of Mlodinow's question should be 1/2 because of his wording.
Finally, the assumption that a family can include two girls named Florida does affect the answer. If you restrict it to one, the probability a second daughter will have any particular unusual name is greater than the same probability for a first girl, because you have to divide all such probabilities by (1-P(first girl's name)) and take a weighted average of all such names. What the result is can't be assumed, but it turns out that the probability Mlodinow should have gotten, based on his assumptions, is greater than 1/2. Not less. It is (1+q)/(3+q), where q=sum(P(Name i)/(1-P(Name i)), and the summation is over all possible names EXCEPT "Florida." That sum is greater than 1 if "Florida" is of average commonality, or rarer.
Can someone tell me what the relevance of the comparative rarity/commonness of the girl's name is? Suppose instead we knew that the girl's name was "Mary". The possibilities would still work out the same:
ReplyDeleteB GM
GM b
GM GNM
GM GM
GNM GM
Ruling out the "two kids with the same name" possibility, we still have two that are both girls out of four, or a 50% chance that both are girls.
So why muddy up the discussion with talk of the rarity of the girl's name?
(note: for some reason it won't let me post here with my google account. So this is anonymous, but my email address is blaisdelltg@gmail.com)
The important point is that we have some information with which to label a subset of our success condition. This is important in that it eliminates the symmetry of G G being a unique solution and splits it into GM GNM and GNM GM, and GM GM given we know at least one of the pair is GM.
DeleteFrom there any process that eliminates GM GM is sufficient to give a 1/2 probability. With the book in front of me and reading the relevant portion, the rare name seems to just be an alternate rational for this fact. I agree with others that this is a weaker line of reasoning, especially since the chapter previous looked at joint probabilities, and causality.
It doesn't communicate how powerful this line of reasoning can be. How small amounts of incomplete information can drastically change the probability of something being true. That said I still think the book is great.
First, the problem Brain addresses here is not the one he asked. It is something like "You think 'Florida’ is an interesting name for a girl. So you often ask random people you meet ‘Do you have a daughter named Florida’? If a person says they do, then you ask how many children they have. What is the probability that such a person, who says they have two children, has two girls?”
ReplyDeleteThe difference between this question, and Brian’s, is that your sample space here is all families of two that include a girl named Florida. In Brian’s version, it should exclude (among others) families where you only know about Florida’s brother Indiana.
Second, Brian got it wrong. “Florida” isn’t the only name that can’t be repeated; no name can. The answer is (2+q-f’)/(4+q-f’), not (2-f)/(4-f). Here, f’=f/(1-f) is the correction for the probability of second daughters’ names other than “Florida,” and q is the sum of all those measures for all names, minus 1. The derivation isn't too hard, but it is too involved for a comment.
To make it simple, let’s say there are only three names possible: Eve, Florida, and Georgia. All else being equal, “Eve” is always twice as likely as either “Florida” or “Georgia,” which are equally likely. It is easy to see that, for a first daughter, e=Pr(D1=E)=1/2 and f=g=Pr(D1=F)=Pr(D1=G)=1/4. It is only slightly more difficult to show that for a second daughter, if no name can be repeated, e'=f'=g'=Pr(D2=E)=Pr(D2=F)=Pr(D2=G)=1/3.
This gives us the following probabilities:
Pr(BF or FB) = Pr(1 boy and 1 girl)*Pr(D1=F) = (1/2)*(1/4) = 1/8.
Pr(FE or FG) = Pr(2 girls)*Pr(D1=F) = (1/4)*(1/4) = 1/16
Pr(EF or GF) = Pr(2 girls)*Pr(D2=F) = (1/4)*(1/3) = 1/12
Pr(2 girls|F) = [(1/16)+(1/12)] / [(1/8) + (1/16)+(1/12)] = (3+4)/(6+3+4) * (1/48)/(1/48) = 7/13.
If we use my formula:
e’ = (1/2)/[1-(1-2)] = 1
f’ = f/(1-f) = (1/4)/(3/4)=1/3.
g’ = g/(1-g) = (1/4)/(3/4)=1/3.
q = 1+1/3+1/3-1 = 2/3.
Pr(2 girls|F) = [2+(2/3)-(1/3)]/[4+(2/3)-(1/3)] = 7/13
In general, common names tend to decrease in probability for the second daughter, as rare names increase. So a rare name increases the chance a girl is a second daughter, over the same chance when you do not know a name.
+++++
So what is the answer to Brian’s question, as asked? It turns out that it is the same problem as “the older child is a girl” version where the answer is 1/2.
Don’t believe me? In that problem, it isn’t the age isn’t that is important. It is that you distinguish one child from the other by ordering them. Any ordering method version works the same, as long as we can assume it doesn’t depend on gender. Alphabetize the children’s names, order them by their places at the dinner table, or … by which child is more noticeable. Noticing something unusual about one, but not the other, is such a method.
Great and I have a keen offer you: Whole House Renovation Cost Calculator remodel outside of house
ReplyDelete